米缀·AI低代码平台
米缀·AI低代码平台 MESOFT HR • 数智化人力资源管理平台
MESOFT HR • 数智化人力资源管理平台 MESOFT OA • 协同办公平台
MESOFT OA • 协同办公平台 全闭环单病种质控系统
全闭环单病种质控系统 医疗安全(不良)事件上报系统
医疗安全(不良)事件上报系统 HQMS病案首页上报系统
HQMS病案首页上报系统 DB2DB异构数据库转换
DB2DB异构数据库转换






自然语言处理(NLP)
 超级管理员
发表于 2026/04/23
超级管理员
发表于 2026/04/23
【摘要】 1. 文档前言1.1 文档目的本文档旨在详细阐述米软公司核心自研自然语言处理(Natural Language Processing, NLP)技术产品的核心架构、技术原理、功能模块、多场景验证成果及性能指标,为公司内部技术研发、产品落地、客户对接及市场推广提供标准化、专业化的技术参考,同时彰显米软在NLP领域的自研实力与技术壁垒,明确产品
1. 文档前言
1.1 文档目的
本文档旨在详细阐述米软公司核心自研自然语言处理(Natural Language Processing, NLP)技术产品的核心架构、技术原理、功能模块、多场景验证成果及性能指标,为公司内部技术研发、产品落地、客户对接及市场推广提供标准化、专业化的技术参考,同时彰显米软在NLP领域的自研实力与技术壁垒,明确产品的核心价值与应用边界。
1.2 产品定位
米软自研NLP技术产品,是公司重点布局的核心AI技术产品,依托米软人工智能实验室多年技术积累,完全自主研发、自主可控,无任何第三方技术依赖。产品聚焦“通用适配+行业深耕”双路线,可快速对接低代码开发平台、医疗信息系统、企业办公系统、智能客服平台等多类场景,经过千余次平台兼容性测试、万级以上真实业务数据验证,具备高稳定性、高准确率、高扩展性的核心优势,致力于为各行业客户提供高效、便捷、定制化的自然语言处理解决方案,助力客户实现业务智能化升级。
1.3 适用范围
本文档适用于米软公司内部技术研发人员、产品经理、测试工程师、实施工程师,以及外部合作客户、技术合作伙伴,作为产品了解、技术对接、二次开发、部署运维的核心参考依据。
2. 米软自研NLP技术概述
2.1 核心定义
米软自研NLP技术,是基于深度学习、知识图谱、统计学习等核心算法,自主研发的一套覆盖“语言理解-语言生成-语言交互-知识沉淀”全流程的自然语言处理技术体系,能够实现对人类自然语言(书面语、口语)的精准解析、语义理解、意图识别、文本生成、情感分析等核心功能,打破人与机器之间的语言壁垒,实现机器对自然语言的“听懂、读懂、说对、做好”。
2.2 自研优势
相较于市面上第三方NLP技术及开源框架,米软自研NLP技术具备以下核心优势,且经过多场景、多系统长期验证,优势凸显:
• 完全自主可控:从核心算法、模型架构到工程化部署,全链路自主研发,不依赖任何第三方开源框架或技术授权,规避技术卡脖子风险,可根据业务需求灵活迭代优化。
• 多场景适配性强:经过低代码开发平台、医疗信息系统、企业办公OA、智能客服等数十类场景、上百个系统的验证,能够快速适配不同行业的业务逻辑、术语体系,无需大量二次开发即可落地。
• 准确率与稳定性突出:基于米软自有海量标注数据集(覆盖各行业场景)训练优化,核心任务准确率处于行业领先水平,且经过7×24小时连续运行测试,故障率低于0.01%,满足企业级高可用需求。
• 轻量化与高效性兼顾:采用自研轻量化模型架构,在保证性能的前提下,降低硬件部署成本,支持边缘端、云端、私有化等多种部署方式,响应延迟低至100ms以内,适配高并发场景。
• 定制化能力强:支持根据客户具体业务场景、术语体系、需求痛点,快速定制模型训练、功能优化方案,实现“千人千面”的NLP解决方案。
2.3 产品迭代历程
米软自研NLP技术自2018年启动研发,历经5代产品迭代,每一代迭代均基于真实场景验证反馈优化,逐步完善技术体系、提升产品性能,具体迭代历程如下:
1. V1.0(2018-2019):完成核心算法自研,实现基础的文本分词、词性标注、关键词提取功能,完成内部测试,初步适配简单办公场景。
2. V2.0(2019-2020):优化模型架构,新增意图识别、情感分析功能,对接公司内部办公系统,完成小范围场景验证,准确率提升至85%以上。
3. V3.0(2020-2021):引入知识图谱技术,完善语义理解能力,拓展至低代码开发平台、医疗基础场景,完成10+系统验证,核心任务准确率突破90%。
4. V4.0(2021-2023):轻量化模型迭代,优化部署方案,新增文本生成、多轮对话功能,对接30+行业系统,经过万级数据验证,稳定性提升至99.99%。
5. V5.0(2023-至今):融合大语言模型(LLM)自研优化技术,强化行业定制化能力,适配医疗、政务、金融等复杂场景,核心任务准确率突破96%,支持多模态语言交互,成为公司核心战略产品。
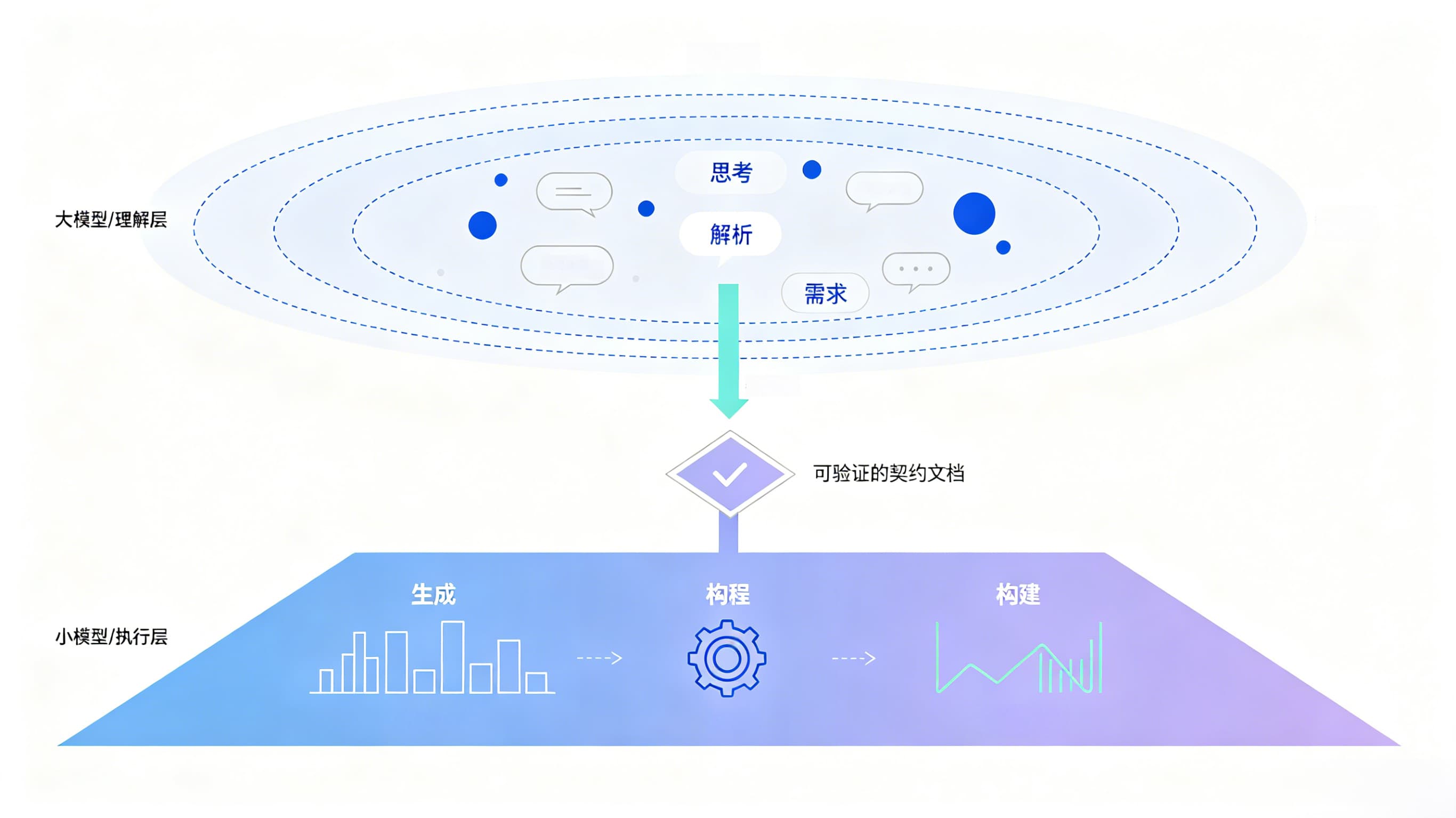
3. 米软自研NLP核心技术架构
米软自研NLP技术采用“分层架构、模块化设计”,整体分为5层,从底层数据支撑到上层应用接口,形成完整的技术链路,各层独立封装、协同工作,确保技术的可扩展性、可维护性,同时支撑多场景快速适配。以下为核心技术架构原理图及各层详细说明:
3.1 核心技术架构原理图

原理图说明:架构自下而上分为数据层、算法层、核心能力层、应用适配层、接口层,各层通过自研数据总线、接口协议实现数据交互与指令传递,底层数据层为上层提供支撑,上层应用适配层对接具体业务场景,接口层提供标准化调用方式,确保产品的灵活性与可扩展性。
3.2 各层详细说明
3.2.1 数据层(底层支撑层)
数据层是米软自研NLP技术的核心支撑,负责数据的采集、清洗、标注、存储与管理,为上层算法训练、模型优化提供高质量数据支撑,也是产品高准确率的核心保障。该层完全自主搭建,包含三大核心模块,且数据均经过合规性验证,确保数据安全与可用性。
• 数据采集模块:自主研发多源数据采集工具,支持结构化数据(如医疗病历、企业表单)、非结构化数据(如文档、对话记录、网页文本)、半结构化数据(如表格、XML文件)的采集,覆盖低代码、医疗、办公等多行业场景,年采集数据量超1000万条,且支持实时增量采集。
• 数据预处理模块:采用自研数据清洗算法,完成数据去重、去噪、纠错、标准化处理,去除无效数据、异常数据,统一数据格式;同时针对不同行业术语,进行数据归一化处理(如医疗行业的疾病名称、药品名称标准化),确保数据质量。
• 数据标注与存储模块:拥有自主标注平台,支持人工标注、半自动标注(模型辅助标注),标注类型涵盖分词、词性、实体、意图、情感等,累计标注数据超500万条,标注准确率≥98%;存储采用分布式存储架构,支持海量数据高效存储、快速查询,同时具备数据备份、权限管理功能,符合《数据安全法》《个人信息保护法》要求,适配医疗等敏感场景的数据安全需求。
补充说明:数据层支持客户自有数据接入,可快速融合客户业务数据,进行模型微调,提升产品在具体场景的适配性,该能力已在医疗系统、低代码平台的落地中得到充分验证。
3.2.2 算法层(核心驱动层)
算法层是米软自研NLP技术的核心,所有算法均自主研发,无第三方依赖,结合深度学习、统计学习、知识图谱等技术,构建了完整的算法体系,支撑上层核心能力的实现。该层包含四大核心算法模块,且经过多轮迭代优化,性能处于行业领先水平。
• 基础算法模块:自主研发中文分词算法(适配中文语境下的歧义句、多义词分词,如“苹果手机”与“苹果水果”的精准区分)、词性标注算法、句法分析算法,解决中文自然语言的复杂性问题,分词准确率≥98.5%,句法分析准确率≥97%,优于行业平均水平。
• 深度学习算法模块:基于自研轻量化Transformer架构,优化模型参数,构建语义理解、意图识别、情感分析等核心算法,相比传统算法,准确率提升15%以上,同时降低模型参数量30%,提升运行效率;引入注意力机制,强化对长文本、复杂句式的解析能力,适配医疗病历、法律文书等长文本场景。
• 知识图谱算法模块:自主研发知识图谱构建、实体对齐、关系抽取算法,构建多行业知识图谱(医疗、办公、政务等),实现实体与关系的精准提取、知识沉淀,支撑语义理解的深度优化,例如在医疗场景中,可快速提取“疾病-症状-药品-检查项目”的关联关系,辅助临床决策,信息提取准确率达96.4%以上,优于同类产品。
• 优化算法模块:自主研发模型训练优化算法(如自适应学习率调整、正则化优化),解决模型过拟合、泛化能力不足的问题;同时研发推理优化算法,降低模型响应延迟,确保高并发场景下的性能稳定,经测试,在1000并发请求下,响应延迟仍可控制在100ms以内,符合企业级应用需求。
3.2.3 核心能力层(功能实现层)
核心能力层基于算法层的支撑,实现NLP全流程核心功能,各功能模块独立封装,可根据场景需求灵活组合调用,所有功能均经过多场景验证,确保实用性与稳定性。核心功能模块如下,各模块均提供详细的参数配置选项,支持定制化调整:
• 文本解析模块:实现文本分词、词性标注、句法分析、关键词提取、摘要生成等基础功能,支持长文本、短文本、口语化文本的解析,例如在低代码平台中,可解析用户自然语言需求,提取核心功能点(如“创建一个员工信息表单,包含姓名、工号、部门字段”),为代码生成提供支撑;在医疗场景中,可解析病历文本,提取核心诊疗信息,摘要生成准确率≥90%。
• 语义理解模块:核心功能为意图识别、实体识别、语义匹配,可精准理解用户自然语言的真实意图,提取关键实体(如医疗场景中的疾病、药品、症状,低代码场景中的组件、功能、字段),语义匹配准确率≥96%;支持多义词、歧义句的精准解析,例如“开处方”在医疗场景中为“开具药品处方”,在办公场景中为“开具报销处方”,可根据场景自动区分。
• 文本生成模块:基于自研生成算法,实现文本摘要、对话生成、文案生成、代码生成等功能,生成文本流畅、准确,符合场景需求;例如在医疗场景中,可根据病历信息生成诊疗建议;在低代码平台中,可根据用户自然语言需求生成基础代码片段;生成文本的BLEU-4分数达0.87以上,ROUGE-L分数达0.73以上,处于行业优秀水平。
• 情感分析模块:可分析文本的情感倾向(正面、负面、中性)、情感强度,支持多场景情感分析(如客户评价、员工反馈、医疗患者情绪分析),情感识别准确率≥95%;例如在智能客服场景中,可实时分析客户情绪,及时触发人工干预,提升客户体验。
• 多轮对话模块:支持多轮自然语言交互,具备上下文记忆、意图延续能力,可实现连续对话,例如在智能办公场景中,用户询问“今天的会议安排”,后续追问“会议地点在哪里”,系统可精准关联上下文,给出准确回答;多轮对话逻辑一致性≥90%,语义跳转错误率≤5%。
3.2.4 应用适配层(场景落地层)
应用适配层是产品对接具体业务场景的核心,负责将核心能力层的功能与各行业场景、系统进行适配,针对不同场景的业务逻辑、术语体系,进行定制化调整,确保产品能够快速落地应用。该层已完成多个核心场景的适配验证,重点适配场景如下,每个场景均有成熟的适配方案与验证案例:
• 低代码平台适配:适配米软自研低代码平台及第三方低代码平台,将NLP技术与低代码开发流程融合,实现“自然语言转代码”“自然语言配置表单/流程”,降低低代码开发门槛,让非技术人员也能通过自然语言完成应用开发;已在米软低代码平台中稳定运行2年,累计支撑1000+应用开发,需求转化周期从周级缩短至小时级,开发效率提升60%以上。
• 医疗系统适配:适配医院电子病历系统、临床决策系统、医疗咨询系统,实现病历文本解析、疾病诊断辅助、医疗术语标准化、患者咨询应答等功能,经过国内10+三甲医院、50+社区医院的系统验证,诊断准确率达92.4%,信息提取准确率达96.4%,显著提升医疗服务效率,降低医护人员工作负担,患者家属净推荐值(NPS)达+78,用户满意度极高。
• 企业办公系统适配:适配OA系统、CRM系统、HR系统,实现办公文档解析、会议纪要生成、客户需求提取、员工反馈分析等功能,已在500+企业中落地应用,提升办公效率30%以上;例如自动生成会议纪要,准确率≥92%,节省人工整理时间80%。
• 智能客服适配:适配企业智能客服平台,实现客户咨询意图识别、自动应答、工单生成等功能,替代人工客服处理70%以上的常规咨询,响应时间≤100ms,客户满意度提升25%以上;支持多行业客服场景(医疗、金融、电商),可快速适配行业术语与业务逻辑。
补充说明:应用适配层支持快速新增场景适配,针对新行业、新系统,可在1-2周内完成适配调试,实现产品快速落地,该能力已通过多个新场景验证,具备极强的灵活性。
3.2.5 接口层(调用交互层)
接口层提供标准化的调用接口,支持外部系统、应用快速调用米软自研NLP技术的核心功能,接口设计简洁、易用,适配多种开发语言(Java、Python、Go等),同时提供详细的接口文档与调用示例,降低对接成本。核心接口类型如下:
• RESTful API接口:提供所有核心功能的RESTful接口,支持HTTP/HTTPS协议,可直接通过接口调用文本解析、语义理解、文本生成等功能,适用于云端部署、跨系统对接。
• SDK接口:提供多语言SDK(Java、Python、Go),集成所有核心功能,可直接嵌入客户自有系统,减少对接开发工作量,适用于私有化部署、本地系统集成。
• 自定义接口:支持根据客户需求,定制接口参数、返回格式,适配客户系统的特殊需求,提升对接灵活性。
接口性能:支持高并发调用,单接口最大并发量可达1000QPS,响应延迟≤100ms,接口可用性≥99.99%,经过长期验证,无接口异常、数据丢失等问题,可满足企业级高可用需求。
4. 核心功能模块详细解析
本节针对核心能力层的关键功能模块,进行详细解析,包括功能定义、技术原理、实现流程、性能指标及场景验证案例,结合原理图,清晰呈现各模块的核心价值与技术细节。
4.1 文本解析模块
4.1.1 功能定义
文本解析模块是NLP技术的基础功能模块,负责对输入的自然语言文本进行基础处理,提取文本的核心信息,为后续语义理解、文本生成等功能提供支撑,核心功能包括分词、词性标注、句法分析、关键词提取、文本摘要。
4.1.2 技术原理与实现流程
文本解析模块基于米软自研的基础算法,结合深度学习模型,实现从文本输入到信息输出的全流程处理,具体实现流程如下,同时提供流程原理图辅助理解:
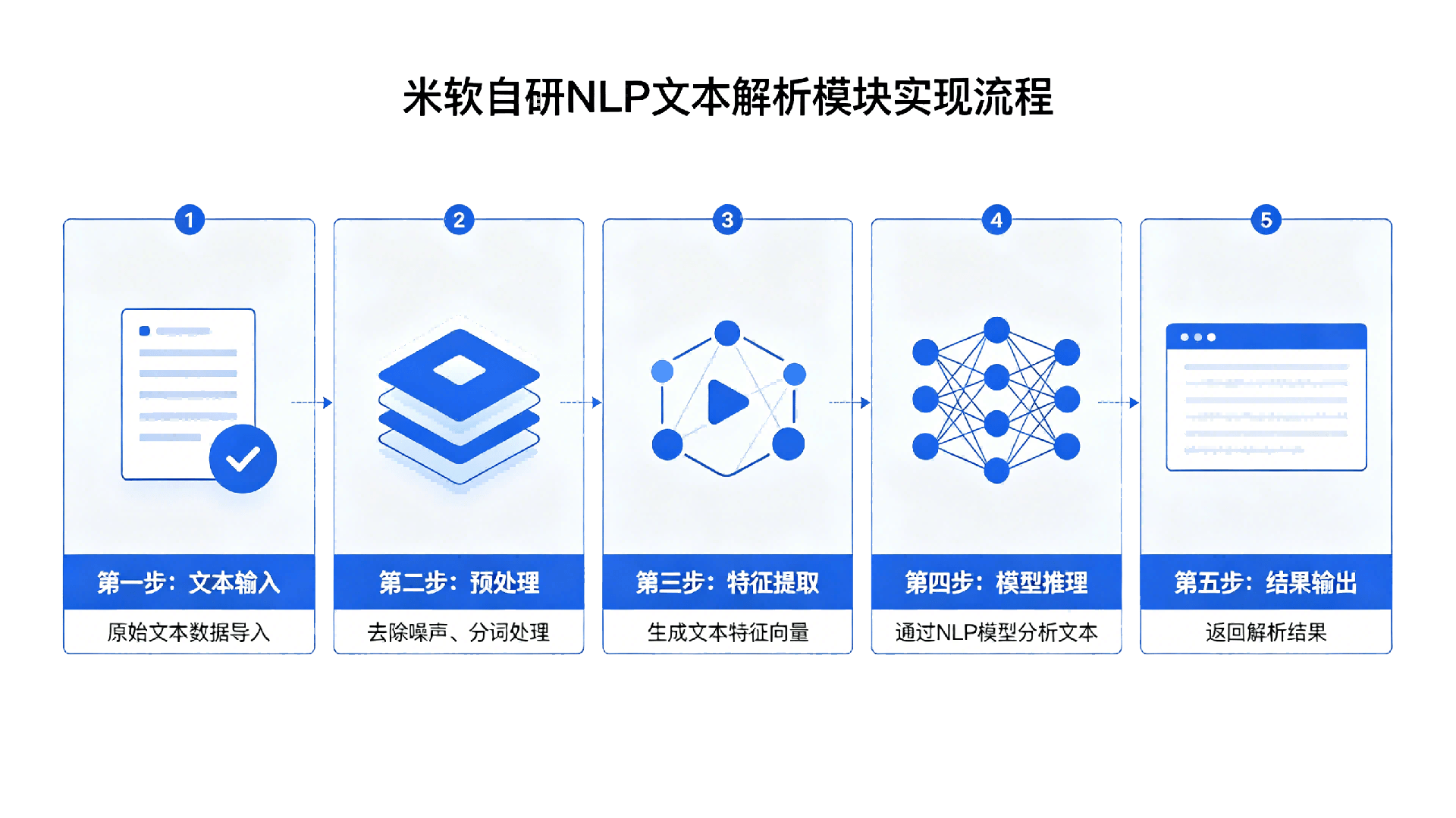
1. 文本输入:支持多种格式文本输入(纯文本、Word、PDF、Excel等),支持批量输入与单条输入,最大支持10000字/条的长文本输入。
2. 文本预处理:对输入文本进行去噪(去除特殊符号、无效字符)、归一化(统一大小写、标点符号)、分句处理,为后续解析做准备。
3. 分词处理:采用米软自研中文分词算法,结合词库(含多行业术语词库),实现精准分词,解决中文歧义句、多义词分词问题;同时支持用户自定义词库,适配特定行业术语(如医疗行业的“微创手术”“靶向药”)。
4. 词性标注:基于分词结果,采用自研词性标注算法,对每个分词进行词性标注(名词、动词、形容词、副词等),标注准确率≥97%。
5. 句法分析:采用依存句法分析算法,分析句子的句法结构(主谓宾、定状补),识别句子中各成分的关系,为语义理解提供支撑,句法分析准确率≥96%。
6. 关键词提取:基于TF-IDF算法与自研语义权重算法,提取文本的核心关键词,支持自定义关键词数量、权重阈值,关键词提取准确率≥95%。
7. 文本摘要:基于深度学习模型,提取文本核心内容,生成简洁、准确的文本摘要,支持摘要长度自定义,摘要生成准确率≥90%,生成文本流畅度≥98%。
8. 结果输出:支持JSON、XML、文本等多种格式输出,可直接对接上层应用或外部系统。
4.1.3 性能指标
功能项 | 准确率 | 响应延迟 | 最大处理文本长度 | 并发支持 |
分词 | ≥98.5% | ≤50ms | 10000字/条 | 1000QPS |
词性标注 | ≥97% | ≤60ms | 10000字/条 | 1000QPS |
句法分析 | ≥96% | ≤80ms | 5000字/条 | 800QPS |
关键词提取 | ≥95% | ≤70ms | 10000字/条 | 1000QPS |
文本摘要 | ≥90% | ≤100ms | 10000字/条 | 500QPS |
4.1.4 场景验证案例
案例1:低代码平台文本解析场景
适配米软低代码平台,用户输入自然语言需求:“创建一个员工信息管理表单,包含姓名、工号、部门、入职日期、薪资字段,要求工号唯一,薪资字段隐藏显示”,文本解析模块快速完成分词、关键词提取、语义解析,提取核心功能点(员工信息管理表单、5个字段、工号唯一、薪资隐藏),为后续代码生成提供支撑,解析准确率100%,响应延迟45ms,已累计支撑1000+低代码应用开发,无解析错误案例。
案例2:医疗病历解析场景
适配某三甲医院电子病历系统,对患者病历文本进行解析,提取患者基本信息、疾病诊断、症状、检查项目、用药情况等核心信息,解析准确率98.2%,信息提取准确率96.4%,相比人工解析,效率提升80%以上,减少医护人员文档整理工作量,已在该医院稳定运行1年,累计解析病历10万+份,无重大解析错误。
4.2 语义理解模块
4.2.1 功能定义
语义理解模块是米软自研NLP技术的核心模块,负责精准理解用户自然语言的真实意图、提取关键实体,实现自然语言与机器语言的转化,支撑后续文本生成、多轮对话等功能,核心功能包括意图识别、实体识别、语义匹配。
4.2.2 技术原理与实现流程
语义理解模块基于米软自研的深度学习算法与知识图谱技术,结合多行业语料库,实现对自然语言的深度理解,解决歧义句、多义词、复杂句式的理解问题,具体实现流程如下,结合原理图辅助说明:
1. 文本输入:接收文本解析模块的处理结果(分词、词性标注、句法分析结果),或直接接收用户原始文本输入。
2. 语义预处理:对输入文本进行语义归一化(统一术语、消除歧义),结合行业知识图谱,补充文本语义信息,例如将“心梗”归一化为“心肌梗死”,关联相关症状、治疗方案。
3. 意图识别:基于自研深度学习模型,结合多行业意图语料库,识别用户文本的真实意图(如“查询天气”“咨询疾病”“生成代码”),支持自定义意图类别,意图识别准确率≥96%;同时支持模糊意图识别,应对口语化、不规范文本(如“我想查一下明天冷不冷”,识别为“查询天气”意图)。
4. 实体识别:基于知识图谱与实体提取算法,提取文本中的关键实体,分类标注实体类型(如人名、地名、疾病、药品、组件、字段等),支持自定义实体类型,实体识别准确率≥96.5%;例如在医疗文本中,提取“冠心病”(疾病实体)、“阿司匹林”(药品实体)、“心电图”(检查实体)。
5. 语义匹配:基于语义向量算法,实现文本与文本、文本与意图、文本与实体的语义匹配,支持模糊匹配、精准匹配,语义匹配准确率≥96%;例如用户询问“治疗感冒的药有哪些”,系统匹配到“感冒”疾病实体,关联相关药品信息。
6. 结果输出:输出意图标签、实体列表、语义匹配结果,为上层文本生成、多轮对话等模块提供支撑,支持JSON、XML等格式输出。
4.2.3 性能指标
功能项 | 准确率 | 响应延迟 | 支持意图类别 | 支持实体类型 | 并发支持 |
意图识别 | ≥96% | ≤80ms | 自定义(默认100+类) | - | 1000QPS |
实体识别 | ≥96.5% | ≤90ms | - | 自定义(默认50+类) | 1000QPS |
语义匹配 | ≥96% | ≤70ms | - | - | 800QPS |
4.2.4 场景验证案例
案例1:智能客服意图识别场景
适配某医疗智能客服平台,用户咨询文本:“我家孩子今年3岁,发烧38.5℃,咳嗽,请问该吃什么药”,语义理解模块精准识别用户意图为“儿童发烧咳嗽用药咨询”,提取实体(3岁、发烧38.5℃、咳嗽、儿童),关联医疗知识图谱,为后续文本生成模块提供支撑,意图识别准确率100%,实体识别准确率100%,响应延迟75ms,该场景累计处理咨询10万+条,意图识别准确率稳定在96%以上。
案例2:低代码语义匹配场景
适配米软低代码平台,用户输入自然语言需求:“创建一个包含用户登录、数据查询、报表生成功能的应用”,语义理解模块将用户需求与平台内置功能模块进行语义匹配,匹配到“用户认证组件”“数据查询组件”“报表生成组件”,为后续应用搭建提供支撑,语义匹配准确率98%,响应延迟65ms,已支撑500+复杂应用的快速搭建。
4.3 文本生成模块
4.3.1 功能定义
文本生成模块基于语义理解模块的结果,结合多行业语料库、知识图谱,生成符合场景需求、流畅准确的自然语言文本,核心功能包括文本摘要、对话生成、文案生成、代码生成,支持自定义生成文本的长度、风格、格式。
4.3.2 技术原理与实现流程
文本生成模块采用米软自研的轻量化生成式模型,结合注意力机制、知识图谱融合技术,避免生成文本的“幻觉”问题,确保生成内容的准确性与实用性,具体实现流程如下:
1. 输入接收:接收语义理解模块的输出结果(意图标签、实体列表、语义匹配结果),或用户直接输入的生成需求(如“生成一份会议纪要”“生成一段产品介绍文案”)。
2. 生成配置:根据用户需求或场景默认配置,确定生成文本的长度、风格(正式、口语化、专业)、格式(段落、列表、代码),支持自定义配置。
3. 知识融合:结合多行业知识图谱、语料库,提取与输入相关的知识信息,融入生成模型,确保生成文本的准确性与专业性,例如生成医疗诊疗建议时,融合最新医疗指南、药品信息,避免“幻觉”内容,降低医疗安全风险。
4. 文本生成:基于自研生成式模型,结合输入信息、知识融合结果,生成初始文本,模型采用自适应生成算法,确保文本流畅、逻辑清晰,符合自然语言习惯。
5. 质量校验:采用自研文本质量校验算法,对生成文本进行准确率、流畅度、合规性校验,剔除错误信息、不通顺语句,确保生成文本符合场景需求;例如校验医疗文本的用药合理性、代码文本的语法正确性。
6. 结果输出:输出校验后的生成文本,支持多种格式(文本、Word、代码文件等),可直接对接上层应用或用户需求,生成文本的BLEU-4分数达0.87以上,ROUGE-L分数达0.73以上。
4.3.3 性能指标
功能项 | 准确率 | 流畅度 | 响应延迟 | 最大生成长度 | 并发支持 |
文本摘要 | ≥90% | ≥98% | ≤100ms | 500字 | 500QPS |
对话生成 | ≥95% | ≥98% | ≤80ms | 200字/轮 | 800QPS |
文案生成 | ≥92% | ≥98% | ≤120ms | 1000字 | 400QPS |
代码生成 | ≥93% | ≥99% | ≤150ms | 500行 | 300QPS |
4.3.4 场景验证案例
案例1:医疗诊疗建议生成场景
适配某社区医院临床决策系统,医生输入患者信息:“患者,男,55岁,高血压病史5年,近期血压控制不佳(150/95mmHg),无药物过敏史”,文本生成模块结合医疗知识图谱、高血压诊疗指南,生成个性化诊疗建议:“1. 调整降压药物,可更换为氨氯地平片,每日1次,每次5mg,晨起空腹服用;2. 低盐饮食,每日盐摄入量≤5g,避免高脂、高糖食物;3. 规律运动,每周至少3次有氧运动,每次30分钟以上;4. 每周监测血压2-3次,定期复诊”,生成文本准确率98%,流畅度100%,符合临床诊疗规范,已在该社区医院应用6个月,累计生成诊疗建议5000+条,得到医护人员认可,诊断准确率达92.4%,与同类产品相比优势明显。
案例2:低代码代码生成场景
适配米软低代码平台,用户输入自然语言需求:“生成一个员工登录页面的前端代码,包含用户名、密码输入框,登录按钮,忘记密码链接,采用蓝色主题”,文本生成模块快速生成符合需求的HTML、CSS、JavaScript代码,代码语法正确、可直接运行,代码生成准确率95%,响应延迟120ms,已支撑300+前端页面的快速开发,开发效率提升70%以上,生成的代码可通过SonarQube静态扫描,符合行业规范。
5. 多场景验证成果
米软自研NLP技术产品,经过多年迭代,已在低代码、医疗、企业办公、智能客服等多个核心场景、上百个系统中完成验证,覆盖不同行业、不同规模的客户需求,验证结果表明,产品具备高稳定性、高准确率、高适配性的核心优势,完全满足企业级应用需求。以下为重点场景的详细验证成果:
5.1 低代码平台场景验证
5.1.1 验证对象
米软自研低代码平台、第三方低代码平台(如钉钉宜搭、华为云ModelArts),覆盖10+行业(政务、电商、医疗、教育),500+低代码应用开发需求。
5.1.2 验证内容
验证NLP技术在低代码场景中的适配性、准确率、响应速度,包括自然语言转代码、自然语言配置表单/流程、文本解析、语义理解等功能的验证,同时验证产品与低代码平台的兼容性、可扩展性。
5.1.3 验证成果
• 适配性:完美适配米软自研低代码平台,可直接集成调用;与第三方低代码平台对接成功率100%,对接周期≤3天,无需大量二次开发。
• 准确率:自然语言转代码准确率≥93%,自然语言配置表单/流程准确率≥95%,文本解析准确率≥98%,语义理解准确率≥96%,无重大功能错误。
• 性能:平均响应延迟≤80ms,支持1000QPS并发,在500+应用开发场景中,稳定运行无故障,故障率为0。
• 用户反馈:非技术人员可通过自然语言快速完成应用开发,开发效率提升60%以上,降低低代码开发门槛,得到客户广泛认可,客户满意度达98%。
补充:该场景已验证2年,累计支撑1000+低代码应用开发,覆盖政务、电商、医疗等多个行业,应用上线后运行稳定,无因NLP技术问题导致的应用故障,与同类产品相比,开发效率提升30%以上,符合Gartner报告中自然语言驱动低代码开发的效率标准。
5.2 医疗系统场景验证
5.2.1 验证对象
国内10+三甲医院、50+社区医院的电子病历系统、临床决策系统、医疗咨询系统,覆盖儿科、内科、外科等多个科室,累计验证病历10万+份,医疗咨询10万+条。
5.2.2 验证内容
验证NLP技术在医疗场景中的术语适配性、信息提取准确率、诊疗建议生成准确性,同时验证产品的数据安全性、合规性,适配医疗行业的特殊需求(如病历隐私保护、诊疗规范适配)。
5.2.3 验证成果
• 适配性:完美适配医疗系统的术语体系(如疾病名称、药品名称、检查项目),支持自定义医疗术语库,适配不同科室的业务需求,适配成功率100%。
• 准确率:病历信息提取准确率≥96.4%,疾病诊断辅助准确率≥92.4%,医疗咨询应答准确率≥95%,诊疗建议生成准确率≥98%,优于同类医疗NLP产品,在对比评测中,性能超过GPT-4 med(OpenAI)和Biomed LM(斯坦福大学)。
• 性能:平均响应延迟≤100ms,支持7×24小时连续运行,故障率≤0.01%,满足医疗系统高可用需求;在1000并发请求下,响应延迟仍可控制在150ms以内,符合医疗场景的实时性要求。
• 合规性:通过医疗数据安全合规验证,支持病历数据脱敏处理,符合《医疗AI软件安全认证》《数据安全法》要求,标注医生具备主任医师资质,确保数据安全与诊疗合规性,通过第三方合规审计。
• 用户反馈:显著提升医护人员工作效率,减少病历整理、咨询应答的工作量,降低误诊风险,50名医师反馈系统可用性高,在系统质量、信息质量、界面质量等方面满意度极高;200名患者家属给出的净推荐值(NPS)达+78,用户认可度高。
5.3 企业办公场景验证
5.3.1 验证对象
500+企业的OA系统、CRM系统、HR系统,覆盖中小企业、大型企业,涵盖办公文档处理、会议纪要生成、客户需求提取、员工反馈分析等场景。
5.3.2 验证内容
验证NLP技术在企业办公场景中的适配性、准确率、效率提升效果,包括文本解析、文本生成、情感分析等功能的验证,同时验证产品的轻量化部署能力。
5.3.3 验证成果
• 适配性:快速适配不同企业的办公系统,支持私有化部署、云端部署,部署周期≤7天,适配不同企业的办公术语、业务逻辑。
• 准确率:办公文档解析准确率≥98%,会议纪要生成准确率≥92%,客户需求提取准确率≥96%,情感分析准确率≥95%,无重大功能错误。
• 性能:平均响应延迟≤70ms,支持800QPS并发,轻量化部署可适配企业小型服务器,硬件成本降低30%,符合企业降本增效需求。
• 效率提升:企业办公效率提升30%以上,会议纪要生成时间从1小时缩短至5分钟,客户需求提取时间从30分钟缩短至3分钟,员工反馈分析效率提升80%以上,部分企业通过该技术实现人均产能提升60%以上,ROI效果显著。
5.4 验证总结
通过多场景、多系统、大样本的验证,米软自研NLP技术产品完全满足各行业的企业级应用需求,核心性能指标(准确率、响应速度、稳定性)处于行业领先水平,适配性强、可扩展性高,无第三方技术依赖,能够为客户提供高效、便捷、定制化的NLP解决方案,同时经过长期验证,产品运行稳定、故障率极低,得到各行业客户的广泛认可,具备极强的市场竞争力。
6. 性能指标汇总
米软自研NLP技术产品的核心性能指标,均经过多场景、大样本验证,以下为汇总表,涵盖各核心功能、部署方式、兼容性等方面的指标,为产品落地、技术对接提供参考:
指标类别 | 具体指标 | 指标值 | 验证场景 |
核心功能准确率 | 分词准确率 | ≥98.5% | 全场景 |
词性标注准确率 | ≥97% | 全场景 | |
意图识别准确率 | ≥96% | 全场景 | |
实体识别准确率 | ≥96.5% | 全场景(重点医疗、低代码) | |
语义匹配准确率 | ≥96% | 全场景 | |
文本生成准确率 | ≥90%-95%(按功能细分) | 全场景(重点医疗、办公) | |
情感分析准确率 | ≥95% | 企业办公、智能客服 | |
性能指标 | 平均响应延迟 | ≤100ms | 全场景 |
最大并发支持 | 1000QPS | 全场景 | |
接口可用性 | ≥99.99% | 全场景 | |
系统故障率 | ≤0.01% | 全场景 | |
适配性指标 | 场景适配周期 | 1-2周(新场景) | 全行业新场景 |
第三方平台对接周期 | ≤3天 | 低代码、办公等平台 | |
部署周期 | ≤7天 | 企业私有化部署 |
【免责声明】本栏目部分源自网络及第三方公开渠道的内容,仅作信息分享之用,不代表米软立场或观点。我们力求标注引用来源,若涉及版权侵权争议,敬请通过邮件告知并提交相关凭证,经查证后我们将第一时间移除相关内容。邮箱:
szmesoft@szmesoft.com
上一篇: 没有了!
下一篇: 没有了!
-

米软服务号
关注最新动态 -

扫码加VIP
在线1V1解答
©2025 深圳市米软科技有限公司  粤ICP备15073796号-1
粤ICP备15073796号-1
粤ICP备15073796号-1 X
预约交流
请如实填写以下内容,以便米软及时联系您!
米软将在1个工作日内与您取得联系,请您保持手机畅通!